The impact of modelling choices in the predictive performance of richness maps derived from species‐distribution models: guidelines to build better diversity models
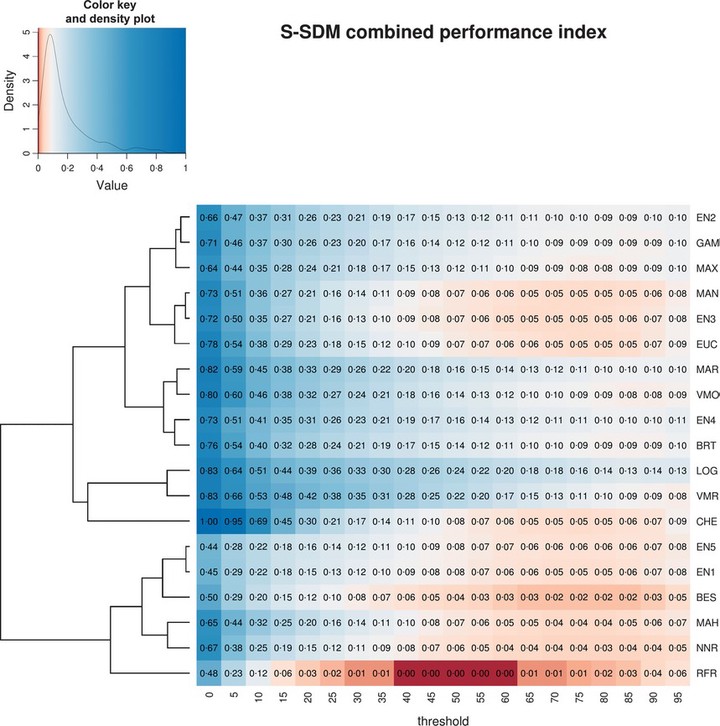 Image credit: Blas M. Benito
Image credit: Blas M. Benito
Abstract
The stacking of species‐distribution models (S‐SDMs) is receiving attention by conservation researchers because this approach is capable of simultaneously predicting species richness and composition. However, the steps required to build S‐SDMs implies at least two choices that influence its predictive performance which have not been extensively assessed: the selection of the modelling algorithm and the application of a threshold to transform the species‐distribution models into binary maps to be added together to build the final S‐SDM. Our goal was to provide guidelines concerning the best combinations of modelling algorithms and thresholds with which to build more accurate S‐SDMs. We generated 380 S‐SDMs of 1224 tree species in Mesoamerica by combining 19 distribution modelling methods with 20 different thresholds using presence‐only data from the Global Biodiversity Information Facility. We compared the predicted richness and composition with inventory data obtained from the BIOTREE‐NET forest plot database. We designed two indicators of predictive performance that were based on the diversity factors used to measure species turnover: a (shared species between the observed and predicted compositions), b and c (the exclusive species of the predicted and observed compositions respectively) and compared them with the Sorensen and Beta‐Simpson turnover measures. Our proposed indexes and the Sorensen index proved suitable as indicators of predictive performance for S‐SDMs, whereas the Beta‐Simpson turnover measure presented issues that would prevent its application to evaluate S‐SDMs. Some modelling methods – especially machine learning and ensemble model forecasting methods performed significantly better than others in minimizing the error in predicted richness and composition. Our results also points out that restrictive thresholds (with high omission errors) lead to more accurate S‐SDMs in terms of species richness and composition. Here, we demonstrate that particular combinations of modelling methods and thresholds provide results with higher predictive performance. These results provide clear modelling guidelines that will help S‐SDM modellers to select the appropriate combination of modelling methods and thresholds to build more accurate S‐SDMs, and therefore will have a positive impact on the quality of the diversity models used to assist conservation planning.